This article is also available in English
此为我为学校科学杂志撰写的文章,发布于 Stowe Science Review 2025 春节特别版。
我还是机器学习初学者,文中若有理解不到位错误的地方,请多包涵,也欢迎在评论中指出。

近期,中国的一家公司声称自己在人工智能领域取得了 560 万美元的突破,不仅超越 ChatGPT 登顶 App Store 排行榜,还让英伟达当天的市值缩水近 6000 亿美元,打破了华尔街对科技公司继续掀起人工智能消费热潮的信心,对美国的科技领导地位造成了明显的打击。这就是 DeepSeek,他们最新的大语言模型 DeepSeek-R1 不仅与 OpenAI 最新的 o1 模型性能相当,且完全开源。DeekSeek究竟是如何完成如此壮举的?其背后原理如何?要回答这些问题,让我们回到机器学习的基本范式之一——强化学习(RL)。
1 截止到2025年1月20日,DeepSeek-R1 发布前。
强化学习的灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。比如说你要训练一条狗狗,如果你尝试用人类的语言与其沟通,那大概率会无功而返。但你可以在它表现好的时候给予其食物奖励,并在它犯错的时候给予适当惩罚。如此一来 ,虽然狗狗无法理解人类语言,但它依旧能从中理解它需要遵守的规则。强化学习即是如此,模型会不断探索环境,并学习哪种策略能使奖励最大化。与监督微调(SFT)不同的是,监督微调的目标是最小化输出与标准答案间的损失。而在强化学习中并不存在标准答案,模型的目标是使奖励最大化。
那么强化学习是如何在大语言模型中工作的呢?早在 2017 年,OpenAI 就发布过一篇关于近端策略优化(PPO)的论文。PPO 属于一种演员-评论家(Actor-Critic)算法,也是强化学习策略梯度(PG)方法的最优实现之一。在该算法中,需要以下 4 个不同的模型:
- 策略模型:用于做出最终决策。在大预言模型中,所谓决策即预测下一个最佳输出单词(语素)。
- 基准模型:作为基准的旧策略模型,用于与新策略模型进行比较,以防止新策略与旧策略之间的差距过大。
- 奖励模型:根据策略模型的决策给出奖励,通常为预训练模型。
- 价值模型:预测在某个状态下的未来期望回报。
策略模型充当演员(Actor),奖励模型则是评论家(Critic)。在训练过程中,策略模型会与价值模型一起训练并互相影响。它们根据彼此的输出结果进行优化来提高文本生成的质量,以更好地符合用户的偏好。
现在让我们详细了解一下每种方法的区别。下面是普通 PG 算法中目标函数的梯度方程:
\( log\pi_\theta\left(a_t\mid s_t\right) \) 是有状态 \( s_t \) 在策略 \( \pi_\theta \) 下采取 \( a_t \) 行动的概率。简单来说,策略会根据其行动是否“做得比预期好”或“做得比预期差”而增减 \( log\pi_\theta \) ,从而使策略逐渐向高回报行为倾斜。这样存在一个问题,一次性改变多少策略并不受限。如此一来,策略模型有几率学坏,它学会了如何满足奖励函数并获得高奖励值,但不完成实际任务,这就是所谓的“奖励黑客”(reward hacking),也可以理解为强化学习的一种过拟合。
为了防止奖励黑客,除了设计出更好的奖励模型,也有新的算法能解决这个问题。比如前面提到的 PPO,其目标函数如下所示:
如你所见,现在该函数计算新策略 \( \pi_\theta \) 下与旧策略 \( \pi_{\theta_{old}} \) 下概率的比值。这个比值表示了新策略与旧策略相比变化多大。这个比率会被截取(clip)到 \( 1-\epsilon \) 与 \( 1+\epsilon \) 之间。如此一来 ,模型就无法一次性过多的改变策略,从而预防奖励黑客的问题。
DeepSeek 则是进一步改善了该算法,推出了“组相对策略优化(GRPO)”。从下图不难看出,相比于 PPO,GRPO 去除了演员-评论家(Actor-Critic)算法中的价值模型(Value Model)(也就是评论家):
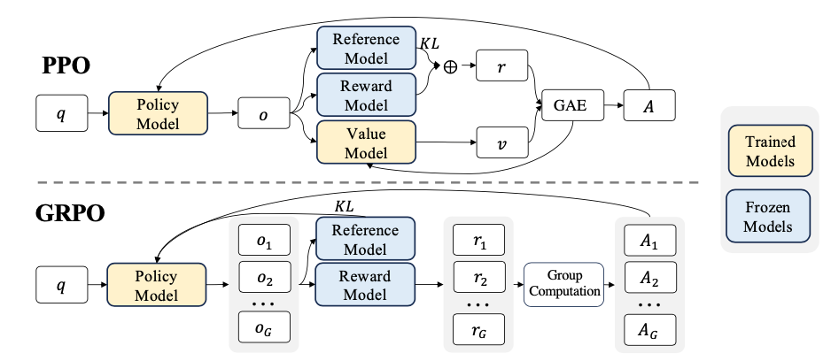
如此一来 ,策略模型变成了唯一在训练中需要调整权重的模型,减少了训练过程中的复杂性和不确定性。与 PPO 不同,GRPO 使用基于组的相对奖励来计算优势。让我们转向 GRPO 的目标函数,看看这是如何做到的:
对于每个输入,它会从新旧策略中同时取样 \( G \) 个输出,并使用奖励模型计算各奖励并取均值,以计算每个样本的相对优势 \( {\hat{A}}_{i,t} \) 。因此,如果某个输出的奖励高于组内平均值,它就会获得正优势,反之亦然。这样,它就不再需要价值模型来预测未来回报,因为模型会与本身的基准(即每组的平均奖励)进行比较。当然,它也使用了与 PPO 相同的剪裁策略,以限制单次策略的变化程度。没有了价值模型也就意味着少了个需要训练的模型,也就节省了硬件资源。这是 DeepSeek 能够以如此之低的成本训练出媲美 OpenAI 的模型的重要原因之一。
举个现实生活中的例子方便大家理解:现在有一所学校,策略模型是学生,负责在卷子上填写答案;奖励模型是自动阅卷系统,负责自动阅卷并评分;价值模型是老师,负责综合评估总体状况并给出指导反馈。现在,我们让学生们互相讨论并比较他们之间的作业,让他们互相学习。学生以这种模式在没有老师(也就是价值模型)的条件下依然能够充分互相发现优缺点并学习改进,并且由于不再需要雇用老师,学校还能减少经费开销(也就是所需硬件资源减少)。
诚然,DeepSeek 在 LLM 以及开源机器学习社区迈出了一大步。看到 “Open'AI ”的闭源模式被开源项目打破,在令人激动的同时也有些许讽刺。当下,人工智能正飞速发展。我们正进入以往科幻电影中才有的世界。希望未来能有更多的研究组织与公司加入竞争,打破垄断,为机器学习创造一个和谐健康的发展环境。