本文同时提供中文版
此为我为学校科学杂志撰写的文章,发布于 Stowe Science Review 2025 春节特别版。
我还是机器学习初学者,文中若有理解不到位错误的地方,请多包涵,也欢迎在评论中指出。

Recently, a Chinese company's claim of a $5.6mn artificial intelligence breakthrough not only overtook ChatGPT to top the charts on App Store but also wiped almost $600bn from Nvidia's market value on the day, shattering Wall Street's confidence that tech companies' AI spending spree will continue and dealing an apparent blow to US tech leadership. This is DeepSeek, with their newest Large Language Model (LLM) DeepSeek-R1 which not only had comparable performance to OpenAI's latest1 o1 model but was also fully open sourced. But how does it work behind the scenes? What exactly did DeepSeek do to bring about such an astounding model? To answer these questions, let's go all the way back to one of the basic paradigms in machine learning – Reinforcement Learning (RL).
1 Up to Jan 20, 2025, when DeepSeek-R1 was released
The idea of RL initially came from the behaviorism in psychology. That is, how an organism, stimulated by rewards or punishments given by the environment, gradually develops an expectation of the stimulus and produces habitual behaviors that will yield the greatest benefit. For example, to train a dog, it won't understand if you just tell it what to do or what not to do. Instead, award it with food when it's doing the right thing and punish it when it does wrong. This way, although the dog won't be able to read the rules, it can learn it from this training process. The same works in the RL process: the model will explore its environment overtime and learn which policy maximize the reward. Unlike Supervised Fine-Tuning (SFT) where the target of the model is to minimize the loss to the model answer, there's no model answer provided in the case of RL. The target of the model here is to maximize the reward.
So how do RL work on an LLM? OpenAI had a paper on Proximal Policy Optimization (PPO) back in 2017. PPO is a type of Actor-Critic algorithm that is used a lot in modern LLMs, it is one of the optimal ways of doing Policy Gradient (PG) methods in RL. In this algorithm, 4 different models are needed.
- Policy model, the model for making the action. In an LLM, the action is to choose the next word when generating sentences.
- Reference model, the model with old policy that provides baseline, this is used to compare with the new policy model.
- Reward model, a pretrained model which gives the award from the action taken of the policy model.
- Value model, the model that predicts the expected future return on current action.
The Policy model act as the actor and the Value model act as the critic. During training, the Policy model and the Value model influence each other and are trained together. They are optimized based on each other's outputs to improve the quality of text generation and better align with user preferences.
Let's get into some details to see the difference between each method. Here's the equation for the gradient of objective function of a normal PG algorithm:
This shows how much the policy parameter should update. \( log\pi_\theta\left(a_t\mid s_t\right) \) is the probability of taking action \( a_t \) given state \( s_t \) under policy \( \pi_\theta \). This basically alter the policy by increase \( log\pi_\theta \) for actions that "did better than expected" and decrease \( log\pi_\theta \) for actions that "did worse than expected"; thus gradually tilting the strategy in favor of high-return behaviors. One problem here is that there's no limit to how much the policy can be changed at once. A situation called reward hacking could happen where the policy model only learnt how to satisfy reward function and get high reward but failed to complete the actual task. Which can be understand as a type of overfitting.
To prevent reward hacking, better reward models should be designed. But there's also new algorithms designed to fix this, which is PPO, its objective function is shown below:
As you can see, now it calculates the ratio of probability from new probability under policy \( \pi_\theta \) and old probability under policy \( \pi_{\theta_{old}} \). This ratio suggests how far away is the new policy changed compared to the old one. And this ratio will be clipped into a certain limit between \( 1-\epsilon \) and \( 1+\epsilon \). So the model can't change its policy in an excessive scope at once, which prevents reward hacking. This was proved a good method and is used by OpenAI team from 2017 even to today for their LLMs.
What the DeepSeek teams did is to come up a new algorithm called Group Relative Policy Optimization (GRPO). It gets rid of the Value model, which is the critic, in the actor-critic model as you can see from this graph:
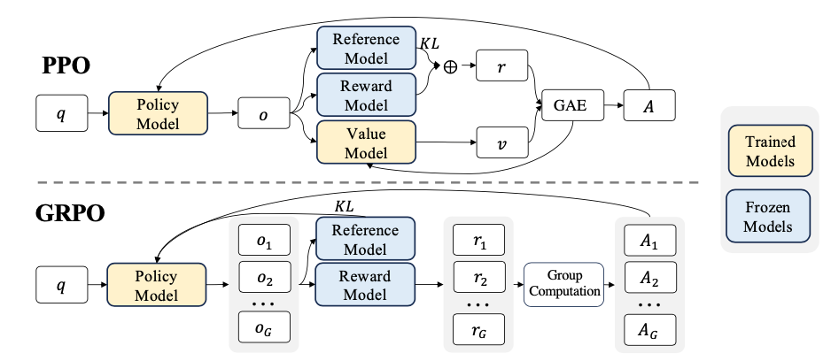
This means the policy model is the only model that needs to be trained during the training. Which reduced complexity and uncertainty during training. Unlike PPO, GRPO uses group-based relative rewards to compute advantages. Let's look at the objective function for GRPO and see what's happened here:
For each prompt, it samples \( G \) outputs from the old policy and score it using the reward model. The average reward from the group is calculated and a relative advantage for each sample \( {\hat{A}}_{i,t} \) is computed. Therefore, if an output's reward is higher than average in the group, it gets a positive advantage and vice versa. This way, we don't need to value model anymore to predict the future returns as the model will compare to its own baseline (which is the mean award for each group). And as you can see, it still used the same clipping strategy as PPO to limit the change in policy at once. Not training a value model alongside the policy model also saves hardware resources. Which is one of the reasons why DeepSeek can train models comparable to OpenAI at such a low cost.
To put it in a real-life example, the policy model is the student who write the answers, the reward model is the marking system who gives the mark, and the value model is the teacher who gives feedback. Now, we ask the students to discuss together about their works and they will learn from other classmates. Students can learn this way without a teacher (which means no value model). Since the teacher is not required, the school can save some money as a result (which means less hardware resource required).
It's indisputable that DeepSeek made a big step forward in LLM as well as the open-source machine learning community. It is very exciting and a bit irony to see "Open"AI's closed-source model has been defeated by an open-source model. Currently, AI is evolving at an unbelievably rapid pace. We are gradually shifting to worlds that used to be reserved for sci-fi films. Hopefully, more research groups and companies will join the competition, breaking the monopoly and creating a harmonious and healthy development of machine learning in the future.